fast-graphrag: Intelligent Graph-based RAG (6x cheaper)
本文为开源社区精选内容,由 circlemind-ai 原创。 文中链接将跳转到原始仓库,部分图片可能加载较慢。
查看原始来源AI 导读
Streamlined and promptable Fast GraphRAG framework designed for interpretable, high-precision, agent-driven retrieval workflows. Install | Quickstart | Community | Report Bug | Request Feature...

Streamlined and promptable Fast GraphRAG framework designed for interpretable, high-precision, agent-driven retrieval workflows.
Install | Quickstart | Community | Report Bug | Request Feature
[!NOTE] Using The Wizard of Oz,
fast-graphragcosts $0.08 vs.graphrag$0.48 — a 6x costs saving that further improves with data size and number of insertions.
Features
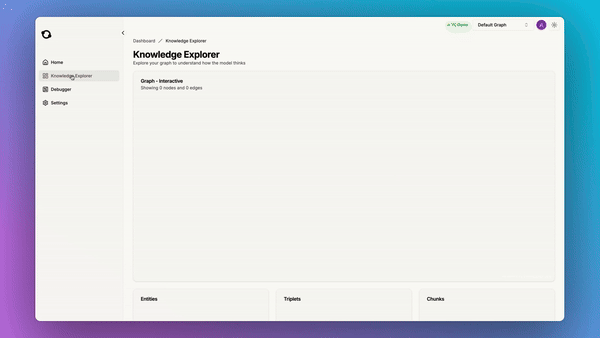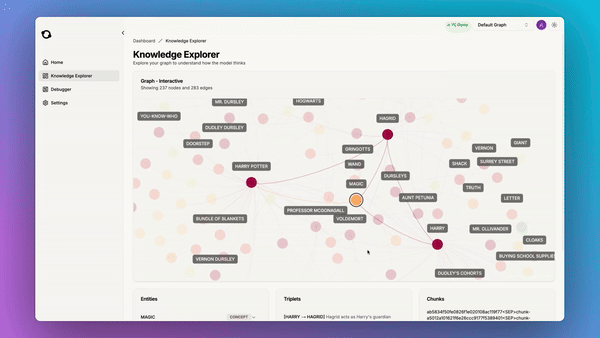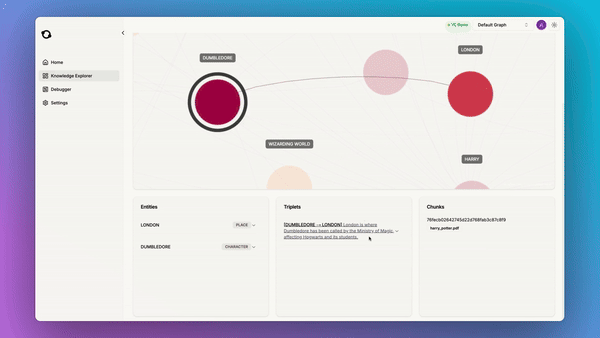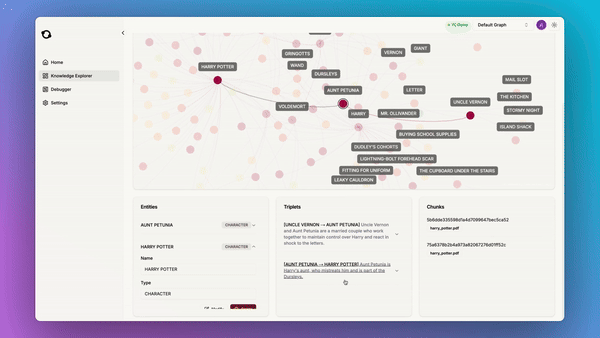
- Interpretable and Debuggable Knowledge: Graphs offer a human-navigable view of knowledge that can be queried, visualized, and updated.
- Fast, Low-cost, and Efficient: Designed to run at scale without heavy resource or cost requirements.
- Dynamic Data: Automatically generate and refine graphs to best fit your domain and ontology needs.
- Incremental Updates: Supports real-time updates as your data evolves.
- Intelligent Exploration: Leverages PageRank-based graph exploration for enhanced accuracy and dependability.
- Asynchronous & Typed: Fully asynchronous, with complete type support for robust and predictable workflows.
Fast GraphRAG is built to fit seamlessly into your retrieval pipeline, giving you the power of advanced RAG, without the overhead of building and designing agentic workflows.
Install
Install from source (recommended for best performance)
# clone this repo first
cd fast_graphrag
poetry install
Install from PyPi (recommended for stability)
pip install fast-graphrag
Quickstart
Set the OpenAI API key in the environment:
export OPENAI_API_KEY="sk-..."
Download a copy of A Christmas Carol by Charles Dickens:
curl https://raw.githubusercontent.com/circlemind-ai/fast-graphrag/refs/heads/main/mock_data.txt > ./book.txt
Optional: Set the limit for concurrent requests to the LLM (i.e., to control the number of tasks processed simultaneously by the LLM, this is helpful when running local models)
export CONCURRENT_TASK_LIMIT=8
Use the Python snippet below:
from fast_graphrag import GraphRAG
DOMAIN = "Analyze this story and identify the characters. Focus on how they interact with each other, the locations they explore, and their relationships."
EXAMPLE_QUERIES = [
"What is the significance of Christmas Eve in A Christmas Carol?",
"How does the setting of Victorian London contribute to the story's themes?",
"Describe the chain of events that leads to Scrooge's transformation.",
"How does Dickens use the different spirits (Past, Present, and Future) to guide Scrooge?",
"Why does Dickens choose to divide the story into \"staves\" rather than chapters?"
]
ENTITY_TYPES = ["Character", "Animal", "Place", "Object", "Activity", "Event"]
grag = GraphRAG(
working_dir="./book_example",
domain=DOMAIN,
example_queries="\n".join(EXAMPLE_QUERIES),
entity_types=ENTITY_TYPES
)
with open("./book.txt") as f:
grag.insert(f.read())
print(grag.query("Who is Scrooge?").response)
The next time you initialize fast-graphrag from the same working directory, it will retain all the knowledge automatically.
Examples
Please refer to the examples folder for a list of tutorials on common use cases of the library:
custom_llm.py: a brief example on how to configure fast-graphrag to run with different OpenAI API compatible language models and embedders;checkpointing.ipynb: a tutorial on how to use checkpoints to avoid irreversible data corruption;query_parameters.ipynb: a tutorial on how to use the different query parameters. In particular, it shows how to include references to the used information in the provided answer (using thewith_references=Trueparameter).
Philosophy
Our mission is to increase the number of successful GenAI applications in the world. To do that, we build memory and data tools that enable LLM apps to leverage highly specialized retrieval pipelines without the complexity of setting up and maintaining agentic workflows.
Fast GraphRAG currently exploit the personalized pagerank algorithm to explore the graph and find the most relevant pieces of information to answer your query. For an overview on why this works, you can check out the HippoRAG paper here.
Open-source or Managed Service
This repo is under the MIT License. See LICENSE.txt for more information.
The fastest and most reliable way to get started with Fast GraphRAG is using our managed service. Your first 100 requests are free every month, after which you pay based on usage.
To learn more about our managed service, book a demo or see our docs.
深度加工(NotebookLM 生成)
基于本文内容生成的 PPT 大纲、博客摘要、短视频脚本与 Deep Dive 播客,用于多场景复用
PPT 大纲(5-8 张幻灯片) 点击展开
fast-graphrag: Intelligent Graph-based RAG (6x cheaper) — ppt
什么是 Fast GraphRAG?
- Fast GraphRAG 是一个智能的、基于图谱的 RAG(检索增强生成)框架 [1]。
- 它专为可解释的、高精度的、由代理驱动的检索工作流而设计 [1]。
- 该工具能无缝集成到现有的检索管道中,直接提供高级 RAG 的能力,无需用户承担设计和构建复杂代理工作流的开销 [2, 3]。
- 它的核心使命是通过构建优质的内存和数据工具,增加全球范围内成功的 GenAI(生成式 AI)应用程序的数量 [3]。
核心优势与成本效益
- 极具成本优势:使用《绿野仙踪》数据集测试显示,其成本仅为传统 GraphRAG 的六分之一($0.08 对比 $0.48) [1]。
- 规模化效益:随着数据规模的增长和数据插入次数的增加,这种成本节省优势还会进一步提升 [1]。
- 高效且低开销:专为大规模运行而设计,不需要繁重的计算资源或高昂的成本要求 [1]。
- 稳定可靠:架构完全异步且强类型,为可预测的工作流提供了稳健的支持 [1]。
主要功能特性
- 可解释且可调试的知识:系统提供的图谱是人类可导航的,允许用户对其进行查询、可视化和更新 [1]。
- 动态数据适应:能够自动生成和完善图谱,从而以最佳方式适应特定领域和本体的需求 [1]。
- 支持增量更新:随着数据的不断演变,系统支持实时更新,并在相同的工作目录中自动保留所有知识 [1, 4]。
- 智能图谱探索:基于个性化的 PageRank 算法探索图谱(原理参考 HippoRAG 论文),寻找最相关的信息,从而提升检索的准确性和可靠性 [1, 5]。
安装与快速上手
- 灵活的安装方式:用户可以通过源码安装(使用 Poetry 以获得最佳性能)或从 PyPi 安装(使用 Pip 以获得稳定性) [2]。
- 简单的环境配置:只需配置 OpenAI API 密钥即可开始;还可以通过设置
CONCURRENT_TASK_LIMIT来控制 LLM 的并发任务数,方便运行本地模型 [2]。 - 易用的 Python API:只需定义领域背景(Domain)、示例查询(Example Queries)和实体类型(Entity Types)即可初始化 GraphRAG [2, 4]。
- 极简的操作流程:通过
insert()方法读入文本数据,随后调用query()方法即可获取问答响应 [4]。
进阶配置与高级应用
- 支持自定义模型:用户可以轻松配置 Fast GraphRAG,使其与各种兼容 OpenAI API 的不同语言模型和嵌入器协同工作 [3]。
- 数据安全机制:提供检查点(Checkpointing)功能,帮助用户在操作过程中避免不可逆的数据损坏 [3]。
- 来源引用追踪:支持使用多种查询参数,例如通过设置
with_references=True,可以在生成的答案中直接包含所用信息的来源引用 [3]。 - 高度定制化的知识提取:允许用户详细设定交互、地点、人际关系等焦点,精确引导大模型提取关键信息 [2, 4]。
开源许可与托管服务选项
- 开源友好:该项目的代码库在宽松的 MIT 许可证下开源,适合广泛的社区使用和二次开发 [5]。
- 官方托管服务:对于希望获得最快、最可靠入门体验的用户,官方提供了专属的托管服务 [5]。
- 免费请求额度:托管服务每月提供前 100 次免费请求,超出部分按实际使用量计费 [5]。
- 获取额外支持:用户可以查阅官方文档,或者通过预约演示(Demo)来深入了解托管服务的详细信息 [5]。
博客摘要 + 核心看点 点击展开
fast-graphrag: Intelligent Graph-based RAG (6x cheaper) — summary
SEO 友好博客摘要
想要提升大语言模型的检索性能并控制成本?Fast GraphRAG 是一款革命性的智能知识图谱 RAG 框架,专为高精度、可解释的检索工作流设计[1]。相比传统方案,它的处理成本直降 6 倍,极大缓解了规模化落地的资金压力[1]。该框架支持数据的实时增量更新,并创新运用个性化 PageRank 算法实现卓越的信息挖掘与探索[1, 2]。无论选择开源部署还是全托管服务,它都能助您告别繁杂的代理系统搭建,轻松且低成本地打造高水准的生成式 AI 应用[2-4]。
核心看点
- 极致降本增效:处理成本相较传统 GraphRAG 方案大幅降低 6 倍,完美支持低资源大规模运行[1]。
- 精准智能检索:依托个性化 PageRank 算法进行图谱探索,提供高精准度且人类可读的知识关联[1, 2]。
- 动态增量更新:支持实时更新与无缝集成,免除复杂代理工作流维护,大幅提升开发效率[1, 3, 4]。
60 秒短视频脚本 点击展开
fast-graphrag: Intelligent Graph-based RAG (6x cheaper) — video
这是一段为您定制的 60 秒短视频脚本,严格按照字数和结构要求编写:
【钩子开场】
GraphRAG成本降六倍?就用它![1]
【核心解说】
**第一段:**成本比传统方案低六倍[1],专为高效检索设计,并支持数据的实时增量更新[1]。
**第二段:**依托个性化算法智能检索[2],不仅精准寻源,其图谱更高度可视化且可解释[1]。
**第三段:**告别繁琐设置[3]!支持开源,其托管服务每月还免费提供一百次调用请求[2]。
【收束】
快来体验 Fast GraphRAG,轻松构建你的低成本 AI 应用吧![4]
课后巩固
本分类的闪卡与测验,帮助巩固记忆
延伸阅读
根据本文主题,为你推荐相关的学习资料